
Project#1: Buffer Pool
撰写本文的目的:记录本人在不参考其他任何形式的解决方法(思路/源码)、仅靠课程提供的资源(课本/参考资料)和Discord中high level的讨论的情况下,独立完成该课程的过程。
欢迎大家和我讨论学习中所遇到的问题。
由于gradescope中对non-cmu students仅开放了Project#0,本文方法仅通过了本地测试,极有可能有错误(并发访问)
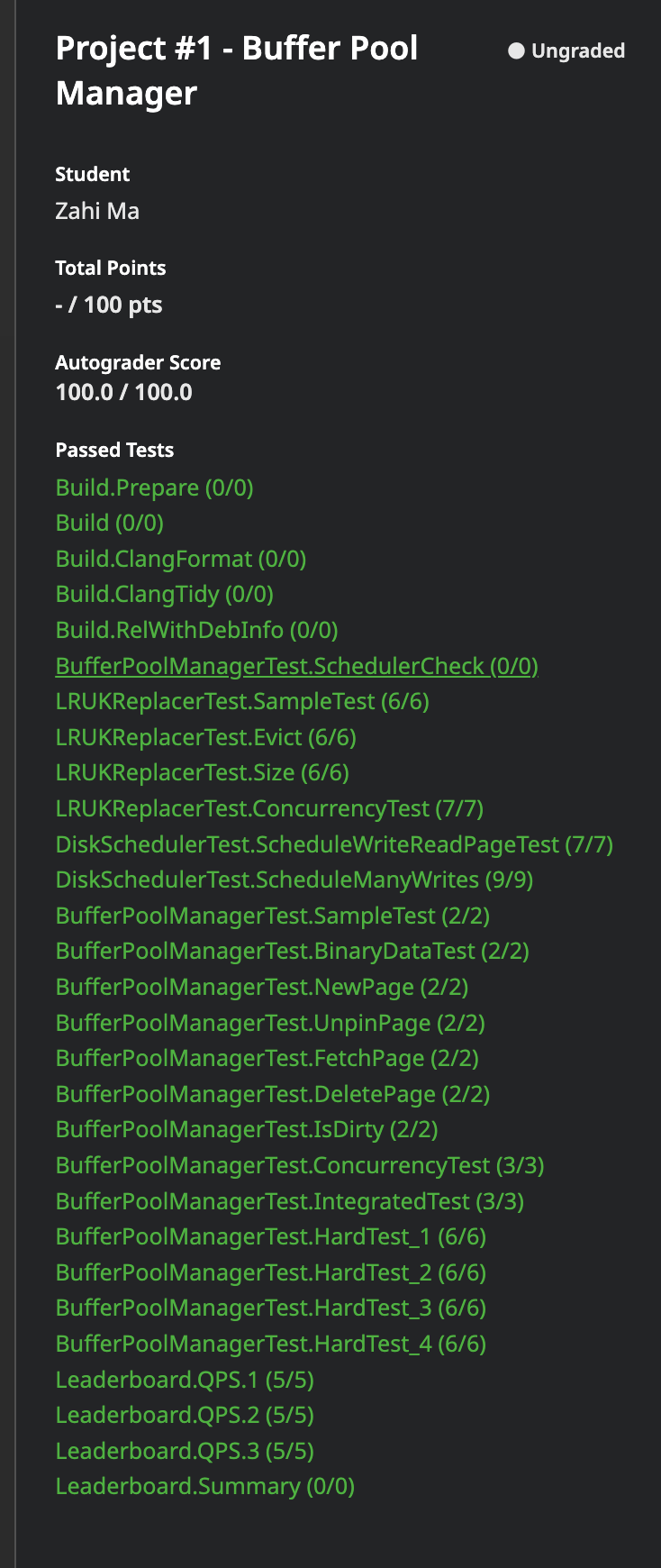
目前通过了GradeScope所有测试并且拿到了100.0/100.0,但是性能较差(与Leaderboard上第一名有十倍的性能差距),打算在下一篇文章记录一下对BPM的性能进行优化,例如本文中提到的DiskScheduler创建的对Request的处理Thread实际上是串行的,后续再保证顺序正确的情况下对其进行适当的并行处理。
Task#1 - LRU-K Replacement Policy
思路:
- 基本可以参考源码中给出的注释,一步一步实现
- 每次
RecordAccess一个Frame时,都会使得leu_replacer的current_timestamp_自增1,方便挑选被evict的frame。 - 在计算
k backwrad distance时,使用UINT32_MAX代替题目中所述的+inf - 由于
LRUNode的成员变量都是私有成员,题目规定不能更改函数或者成员的signature,因此需要自己定义多个setter和getter方法 - 为了方便
Evict方法的实现,可以在LRUNode中实现GetKDistance方法
Size
直接返回维护的curr_size_。
RecordAccess
- 判断frame_id是否有效
- 判断node_store中是否已经存在对应该frame_id的LRUNode
- 若未存在,则创建临时LRUNode,并更新node的访问历史,将其插入node_store_
- 若已经存在,则只是更新访问历史
- lru_replacer的current_timestamp自增1
SetEvictable
按照注释一步一步实现,需要注意更新curr_size_
Evict
- 定义两个临时变量记录最大的time stamp difference和对应的frame id
- 定义一个vector,记录所有k backward distance为+inf的frame id
- 遍历一遍frame node
- 通过最大的time stamp difference,若为+inf,则遍历vector找到earliest access history以及对应的frame id
Remove
按照注释实现即可
Bugs
- [✅] 未给方法中任意位置加锁时能够通过测试,可能本地测试并没有涉及到对某个成员变量的竞争。但是加锁后测试就会卡住
- 🐽,破案了:在
SetEvictable函数中,一开始就获得了latch,但是并没有在每个return分支释放latch
Tests

Task#2 - Disk Scheduler
思路:
- 可能有多种实现方法,我的思路是
Scheduler方法只将给定的DiskRequest对象put进request_queue_队列 - 自己实现一个
ProcessRequest方法,用于对给定request调用disk_manager的读写Page方法 - 而
StartWorkerThread则在析构函数put一个std::nullopt之前一直循环,从request_queue_中不断取出request并且通过ProcessRequest方法创建一个线程来完成对request的读写
需要注意的是:
- 首先,通过
cppreference熟悉std::promise和std::future等概念- 主要是通过
__state成员变量实现shared_memory方式的线程间异步通信 - 需要注意的是只能对
std::promise对象调用一次get_future方法
- 主要是通过
- 其次,通过类的
none-static方法创建thread时,需要注意显示地给出方法地址,并且给出对象地址,接着输入参数
这里只写一下StartWorkerThread的实现思路
StartWorkerThread
唯一需要注意的是,我维护了一个std::vector<thread>来实现对所有thread的join
- 在DiskScheduler 析构之前:Put std::nullopt,
- 循环对request_queue中的request创建thread来进行process:
- 从 request_queue_ 中获得队伍首部的request
- 创建执行 WritePage/ReadPage的 thread
- 等待thread join
- 循环对request_queue中的request创建thread来进行process:
BUGs
- [✅] BUG: std::abort
std::promise只能被使用一次:
- 只能调用一次
std::future获得future对象
- 在对
promise1的future1调用get函数后会报std::abort()- 不调用future2的get时也会报错
- 对第一个request创建完第一个thread后,不知为什么
WorkerThread就卡住了,无法取得第二个request并创建第二个thread - 似乎是因为将
request的引用传进了子线程中,但是在主线程中随着执行出了作用域,request被析构了- - [✅] 尝试传入this_request的移动
Test

Task#3 - Buffer Pool Manager
通过参考Page,LRU K Replacement Policy和Disk Scheduler的源码实现,完成时过程比较曲折,花了中秋节一下午和晚上完成,并且只通过了本地测试,并发问题肯定很严重。等gradescope开了再继续完善。
源码中给的提示还是比较清晰,因此实现过程虽然曲折但也还算顺利。但有一些我自己踩过的坑或bug,在最后统一写出。
Learning Note
- 如果在if之前对mutex进行过lock,需要在每个if分支(若有return)中unlock
- 多线程在进行数据同步的时候,如若使用promise和future,一定不要忘了在指定线程中使用future对象实例的get方法,等待线程任务的完成
- DiskManager:
WritePage(page_id_t page_id, const char *page_data)- page_id:Disk Page的id
- page_data:是Memory buffer pool中存储Disk Page所在frame的地址
ReadPage(page_id_t page_id, char *page_data)- page_id: Disk Page的id
- page_data: 也是将Disk Page读入内存所在frame的地址
给出一些比较重要的实现
NewPage
- 通过free_list_判断是否有frame上无page
- 若free_list上无,则通过replacer判断是否有evictable frame
- 若replacer无evictable,则返回nullptr
- 若有eviictable,AllocatePage()获得新 page_id,调用replacer.Evict()获得对应frame_id,
判断frame_id对应的page_id的Page Object是否dirty- 若dirty,则将其写会Disk,将Page Object置空
- 若不dirty,则将Page Object置空
将置空的Page Object与新page_id绑定,将page_id和frame_id存入page_table
通过replacer将frame Pin(evictable false)
- 若free_list上有free frame for new page()
- 获得free_frame_id
- 获得新page_id
- 将为page_id获得Page对象
- 将page_id与frame_id绑定
- 将frame Pin
- 若free_list上无,则通过replacer判断是否有evictable frame
FetchPage
0 查看buffer pool中是否有该Page,通过GetPageByPageId,
若有,则返回Page*
若无:
- 查看buffer pool中是否有空frame,即free_list_上是否有frame_id
- 若buffer pool中无空frame,则通过replacer判断buffer pool上是否有evictable frame
- 若无evictable,则说明buffer pool中没有该Page,并且因为无evictable,也无法从disk中读入
- 返回null_ptr
- 若有evictable frame,
- 通过replacer evict该frame,并获得frame_id
- 判断frame_id对应的page_id的Page Object是否dirty
- 若dirty,则通过创建DiskRequest,将其写回Disk,并将PageObject置空
- 若不dirty,则将Page Object置空
- 创建DiskRequest,将page_id对应Disk Page从Disk中读出到Buffer frame中,并用Page Object管理
- 将page_id与frame_id绑定
- 通过replacer将frame pin
- 若无evictable,则说明buffer pool中没有该Page,并且因为无evictable,也无法从disk中读入
- 若buffer pool中有空frame
- 获得free_frame_id
- 从pages_上获得unused page作为读入Disk Page的管理Page
- 创建request将page读入,并将管理page的信息更新
- 将page_id与frame_id绑定
- Pin frame
- 若buffer pool中无空frame,则通过replacer判断buffer pool上是否有evictable frame
UnpinPage
- 判断page_id对应的Disk Page是否在buffer中
- 若不在,则返回false
- 若在,取得该Page对象,判断pin count是否为0
- 若为0,则返回false
- 若否,则降低pin count,若降低后为0,则调用replacer设置frame为evictable
- 根据参数is_dirty设置Page对象的is_dirty成员
- 返回true
DeletePage
- 首先判断page_id是否在pages_中,即是否在buffer pool中
- 若不在,则直接返回true
- 若在,则判断其是否pinned
- 若pinned,则说明无法删除,返回false
- 若不是pinned,开始进行Delete:
- 获得其frame_id,将page_id从page_table中删除
- 调用replacer不再track该frame,并且将frame加入到free_list中
- reset其对应的Page对象
- 调用DeallocatePage释放Disk上的Page
LearningNote
如果在if之前对mutex进行过lock,需要在每个if分支(若有return)中unlock
多线程在进行数据同步的时候,如若使用promise和future,一定不要忘了在指定线程中使用future对象实例的get方法,等待线程任务的完成
DiskManager:
WritePage(page_id_t page_id, const char *page_data)- page_id:Disk Page的id
- page_data:是Memory buffer pool中存储Disk Page所在frame的地址
ReadPage(page_id_t page_id, char *page_data)- page_id: Disk Page的id
- page_data: 也是将Disk Page读入内存所在frame的地址
Bugs
- [✅] BUG:在NewPage中第二次latch_.lock()时,debug程序中断
- 查阅资料:可能是由于在一个线程中对非递归锁多次执行lock,导致异常
- - [❎] 尝试使用
recursive_lock - - [✅] 破案了,是因为某个函数中的一个if条件返回时忘记释放latch_
- - [❎] 尝试使用
- [✅] BUG:Flush Dirty Data之后,Fetch不到原来的数据

- [✅]emmm,从promise获得future对象后,忘记使用get方法等待Request的完成,使得主线程在子线程未将disk page content写入内存,就判断page content是否相同了
- [✅] BUG:在做Test2时又遇到了上述问题
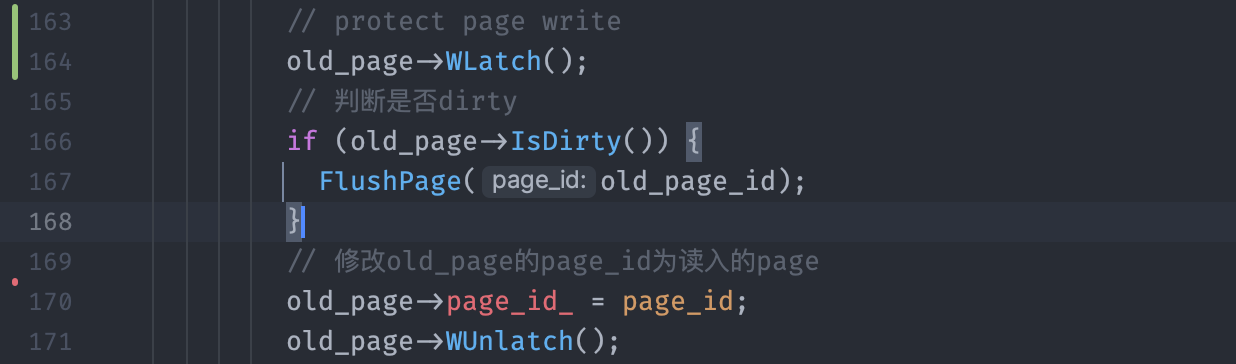
- 检查出一个bug:在NewPage中,如果通过evict一个frame来腾出位置,需要将原先old_page从page_tables_中删除
- [✅] 发现错因:
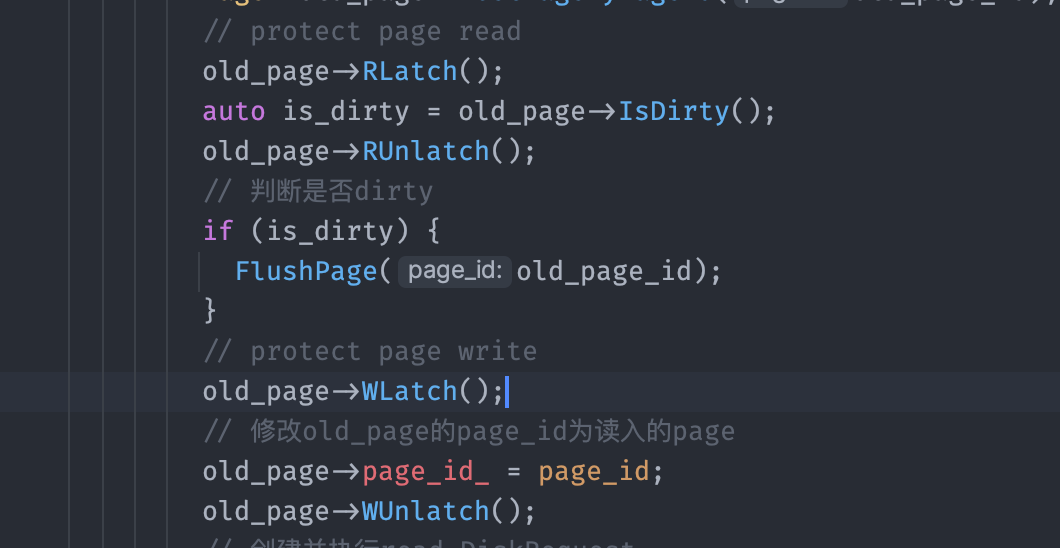
- FlushPage时:写回的应该是old_page_id,而我在NewPage中对DirtyPage进行写回时,传递的实参时新读入Page的id
Test
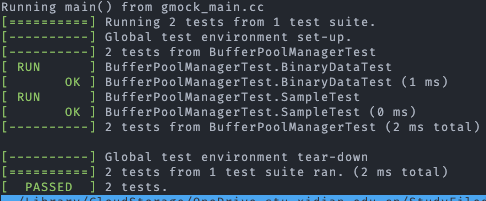
记录通过
GradeScope线上测试的过程
GradeScope
Learning Notes
Try writing local test cases (it is faster and you learn more by doing so anyway), don’t try to use gradescope as debugger
可以打log,使得gradescope输出,然后复现test
dead lock & possible synchronization problems
Like improper acquire & release latches
- You can ensure no synchronization problem by using
std::scope_lock, then if the segfault persists, check the other part of your program
先通过
GradeScope的基础测试,后续再考虑做Leaderboard Task

- assert() is an another one
- [20:47]Sometimes the evaluation inside assertion will cause concurrency inconsistency
Memory leaking can be detected by the sanitizer, if any log is printed under the test section on Gradescope
- Try writing some local tests to reproduce the case
- [16:58]And you may recheck if the semantic of the function is consistent with handout
- [16:59]As said here, Check your return value behavior for LRUKReplacer::Evict
- The top submissions that I saw from students (in previous semesters) require a rethinking of data structures. It is helpful to have done something like cachelab from the prerequisite course: https://csapp.cs.cmu.edu/3e/cachelab.pdf (已编辑) You can go very far with the same algorithms ( https://codegolf.stackexchange.com/questions/215216/high-throughput-fizz-buzz/ comes to mind), but typically if you want to completely beat the performance of other similar solutions, you’ll need to come up with an insight or idea that they don’t have
- You do not to need to lock the page when incrementing the pin_count_
- [18:52]Instead you will want to do it using the latch of BPM
- Please decouple the Page Latch versus the BPM Latch. The former one is needed when you perform operations on the inner Page Data.
- You will NOT need to hold/acquire the Page Latch if you are going to increase the pin count, and race condition will be introduced if you do so.(why?)
- Try rethink why we need the latch and in which case will the latch block your operations, especially between threads
- Write your own test cases to try reproducing the failure cases.
- You may add some logs, see the handout for details.
- 在
buffer pool中的page也一定在page_table中
Code Format
注意项目路径不要过长,否则会
make format失败
make format可以自动更改代码格式,除了一些必须改动代码内容的需要通过make check-clang-tidy-px来检测并手改。do not use 'else' after 'return':- 保险起见:提前定义一个return变量,每个if分支对其进行赋值,最后统一返回该值
- 可能会多构造一次临时对象实例,但我觉得无伤大雅?
- 某些情况下可以直接删除else
- 保险起见:提前定义一个return变量,每个if分支对其进行赋值,最后统一返回该值
Tests
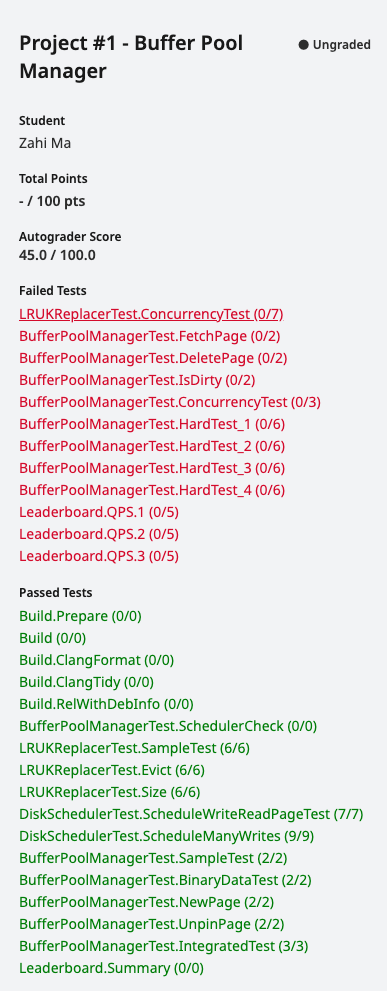
问题:一个一个解决吧
LRU Replacer- 并发访问问题
Disk Scheduler:没问题Buffer Pool Manager:问题很多
LRUKReplacerTest.ConcurrencyTest
1 | > ctest . -R ^LRUKReplacerTest.ConcurrencyTest$ --no-tests=error --verbose |
- - [✅] Deadlock?
- 先将
latch_持有的粒度最大化:内部访问shared data structure的函数都从一开始就lock直到return之前再unlock - 接着逐渐缩小
latch_持有的粒度 - - [✅] 🐽:破案了。。。又是函数中
if的某个分支忘记unlock。。。后续一定牢记
- 先将
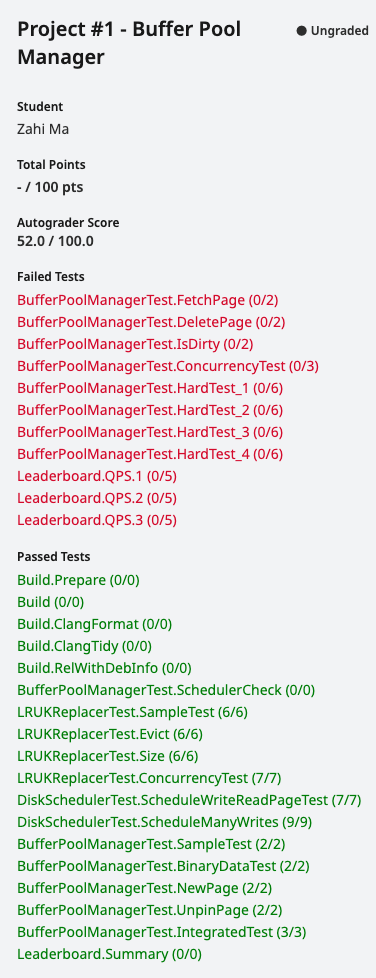
BufferPoolManagerTest
很多测试未通过:
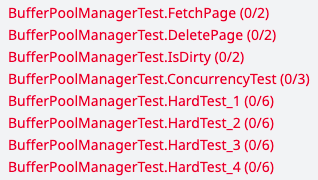
one by one:
FetchPage
1 | 10: Test command: /autograder/source/bustub/build/test/grading_buffer_pool_manager_test "--gtest_filter=BufferPoolManagerTest.FetchPage" "--gtest_also_run_disabled_tests" "--gtest_color=auto" "--gtest_output=xml:/autograder/source/bustub/build/test/grading_buffer_pool_manager_test.xml" "--gtest_catch_exceptions=0" |
- - [✅]
Unpin相关操作逻辑有bug- 影响
UnpinPage逻辑的一些shared data structurepage_table_Page::pin_count_- - [❓] 尝试
NewPage和FetchPage时,都初始化pin_count_为1。并且在DeletePage时,将Page::pin_count_设置为0- 修改后遇到新bug:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2167: Note: Google Test filter = DiskSchedulerTest.ScheduleManyWrites
67: [==========] Running 1 test from 1 test suite.
67: [----------] Global test environment set-up.
67: [----------] 1 test from DiskSchedulerTest
67: [ RUN ] DiskSchedulerTest.ScheduleManyWrites
67: /autograder/source/bustub/test/storage/grading_disk_scheduler_test.cpp:68: Failure
67: Expected equality of these values:
67: std::memcmp(buf, data_pages[100 - 1], sizeof(buf))
67: Which is: 8
67: 0
67:
67: [ FAILED ] DiskSchedulerTest.ScheduleManyWrites (18 ms)
67: [----------] 1 test from DiskSchedulerTest (18 ms total)
67:
67: [----------] Global test environment tear-down
67: [==========] 1 test from 1 test suite ran. (18 ms total)
67: [ PASSED ] 0 tests.
67: [ FAILED ] 1 test, listed below:
67: [ FAILED ] DiskSchedulerTest.ScheduleManyWrites
67:
67: 1 FAILED TEST - 影响的测试应该是串行多次读写?可能是错误修改了不该修改的
page的dirty/pin_count_导致的 - - [✅] 尝试修改
GetFreePageForPageId中的pin_count_为1,解决新bug。 - 为什么同一个文件上传多次:有的时候会
fail有的时候pass?太玄学了?
- 修改后遇到新bug:
- - [✅] 尝试修改
FetchPage:每次访问在BufferPool中的Page,都access and pin_count_++
- - [❓] 尝试
- 影响
- - [✅] 有很严重的
Memory Leaks:9处。。。🐽- 通过更改
FetchPage的逻辑,也将其解决了。
- 通过更改
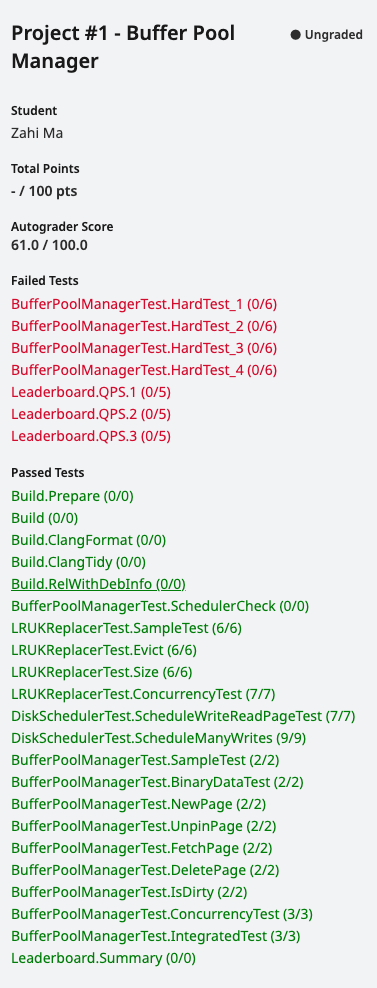
DeletePage/IsDirty/ConcurrencyTest
- 是因为
FetchPage处理存在于Buffer Pool中Page的逻辑有问题,导致了这么多测试失败。 - 下次需要自己多多思考了,注释不可能像伪代码一样将所有情况的处理都写下来,需要自己真正理解这个函数在做什么
FetchPage实际上就是Execution Engine调用的,然后调用UnpinPage来告诉BPM它对Page是否进行Write,接着BPM会决定该如何处理Page以及Replacer会如何处理- 简单来说,
pin_count_类似于reference_count,而NewPage,FetchPage会增加pin,而UnpinPage会相应的减少pin
- 简单来说,
- 对于已经在
Buffer Pool中的Page,可能会有多个worker正在或者已经fetch,因此需要pin++,并且调用replacer来记录访问log
- - [✅] 对于相同的
submission file,ConcurrencyTest也会有时失败有时成功,搞不清楚。可能每次用于测试的数据不同?- 需要先扩大锁持有的范围/粒度
HardTests(1-4)
- [✅]HardTest_1
1 | 15: Test command: /autograder/source/bustub/build/test/grading_buffer_pool_manager_test "--gtest_filter=BufferPoolManagerTest.HardTest_1" "--gtest_also_run_disabled_tests" "--gtest_color=auto" "--gtest_output=xml:/autograder/source/bustub/build/test/grading_buffer_pool_manager_test.xml" "--gtest_catch_exceptions=0" |
- [✅] HardTest_2 - 4
- - [ ] 和
Address Sanitizer相关,可能是内存泄漏?也可能是并发访问导致的- 似乎
FetchPage和UnpiPage还是有问题 page_table_访问抛出了out_of_range- - [❎] 给LRUNode设置锁
- 但实际上
Replacer自己维护了一个锁,并且我也给每个成员函数上了该锁,不应该会有多个线程同时访问一个LRUNode
- 但实际上
- - [✅] 尝试扩大
BPM中每个方法持有latch_的范围粒度- 扩大到整个函数期间都拥有
latch_,有一定效果,但是不多,解决了FetchPage和UnpinPage的问题 - - [✅] 需要解决函数调用者和被调用者可能同时获得同一个锁:效果显著。
性能可能有大问题- [✅] 递归锁/ScopeLock
- [ ] 先释放再调用:可能会在释放与获得之间的空隙发生竞争
- 扩大到整个函数期间都拥有
- 似乎
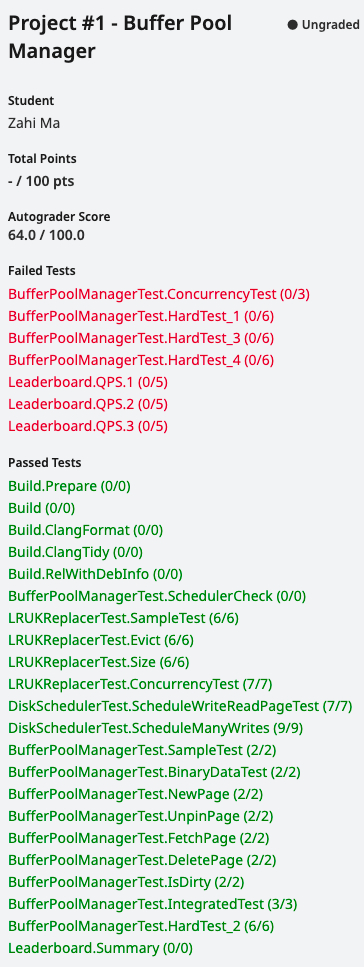
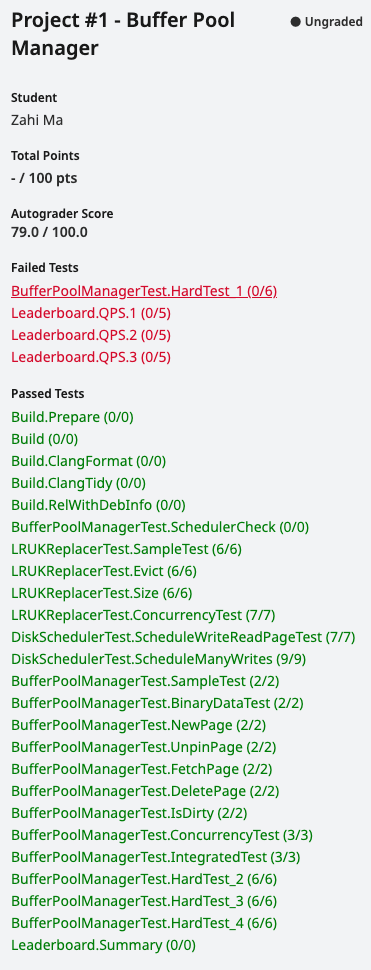
- [✅] 还剩下一个HardTest-1:可能由于Page对象的读写锁没有正确地获取和释放,导致测试文件中的内存泄漏?
- [❎] 尝试修改
BPM对Page对象读写锁的持有范围:需要注意的是,W和R是读写锁的意思,而非从disk中read或者write- 会有许多调用者和被调用者持有相同锁的问题:但这次是读写锁
- 错误:
- 获得读锁期间,创建临时变量获得需要的内容
- 错误:
- 会有许多调用者和被调用者持有相同锁的问题:但这次是读写锁
- [✅] 其他原因:仍然是
AddressSanitizer相关问题:- [❎] BPM中我自己写工具函数都没有对Page进行访问保护
- 改了,但仍是无法通过该测试
- [❎]
RecordAccess中逻辑错误invalid frame id- 修复了,但是对该问题无影响
- [✅]
replacer的实现有问题- - [✅] 没有保证并发安全:
- - [✅]
replacer维护一个scope latch - - [✅]
LRUNode维护一个latch并且定义工具函数来获取和释放锁 - - [✅] 成员变量含有
mutex的类,不能进行copy等操作,因此无法插入node_store<frame_id, LRUNode>中- 需要将该数据结构改为
node_store unordered_map<frame_id, std::shared_ptr<LRUNode>>
- 需要将该数据结构改为
- - [✅]
- - [✅] 之前对
LRUNode都是构造临时对象,这次尝试在node_store中维护指针- - [✅] 需要
new获得堆内存,**必须显式地使用delete释放: 不然会造成内存泄漏,**有时候认为自己在所有地方都使用了delete但仍然会有内存泄漏,这时使用smart pointer在C++中,局部类对象变量取地址和使用`new`操作符有重要的区别。这区别在于对象的生命周期、内存管理和访问方式:
1. 对象的生命周期:
- 局部对象变量取地址:当你取一个局部对象的地址,对象的生命周期仗赖于其定义的作用域。一旦超出该作用域,对象将被销毁,且你的指针将成为悬垂指针(dangling pointer),因为它引用的内存已经释放。
- 使用new:使用
new创建的对象位于堆内存,它的生命周期在你显式调用delete来释放内存之前会一直存在。这意味着你可以在超出定义作用域的地方继续访问这个对象,只要你小心管理内存。2. 内存管理:
- 局部对象变量取地址:不需要显式管理内存,对象的内存分配和释放是由编译器自动处理的。
- 使用new:你需要手动分配和释放内存。使用
new来创建对象后,必须使用delete来释放这些对象的内存,否则会导致内存泄漏。3. 访问方式:
- 局部对象变量取地址:你可以直接通过指针来访问对象的成员和方法,就像你访问其他对象一样。
- 使用new:你同样可以通过指针来访问对象的成员和方法,但你必须使用箭头运算符(
->),因为你操作的是一个指向对象的指针。总之,取局部对象的地址和使用
new都有各自的用途和适用情况。如果你需要一个对象在函数调用之后继续存在,使用new来在堆上分配内存可能是一个好选择。但请务必小心管理内存,避免内存泄漏。如果对象的生命周期仅在函数内部有效,取地址通常更为简单和安全。
- - [✅] 直接使用
shared_ptr,避免内存泄漏。啊,真香
- - [✅] 需要
- 但仍然未能解决`HardTest_1`的问题
- - [✅] 没有保证并发安全:
🌟- [✅]
disk_scheduler的实现有问题:偶尔会出现DiskSchedulerTest.ManyWriteTest失败,成功和失败间隔出现:事实证明,该Test的内存泄漏问题是由于Disk_Scheduler的实现有问题导致的,并非真的是内存泄漏问题。- - [✅] 保证并发安全:在
backgroundThread中创建多个thread会对shared_data_structure竞争?- - [✅] 不需要给
Schedule和WorkThread中加锁,对request_queue对象本身访问就是并发安全的,因此只需要给ProcessRequest增加获取锁和释放锁
- - [✅] 不需要给
- 但仍然未能解决
HardTest_1的问题 - - [✅] 仍然有极其低的概率出现失败
1/4?- 读写相同Page的多个
thread无法按照给定顺序执行:- - [✅] 先使用
join串联执行,确保正确性:
- - [✅] 先使用
- 读写相同Page的多个
- - [✅] 保证并发安全:在
- [❎] 打
log,复现test:必然有用,持续使用ing经过上述对
replacer和disk_schedular的实现,HardTest_1的两种报错:- 1.
1
2
3
4
5
6
7
8
9
10
11
12
1315: Running main() from gmock_main.cc
15: Note: Google Test filter = BufferPoolManagerTest.HardTest_1
15: [==========] Running 1 test from 1 test suite.
15: [----------] Global test environment set-up.
15: [----------] 1 test from BufferPoolManagerTest
15: [ RUN ] BufferPoolManagerTest.HardTest_1
15: Stack trace (most recent call last) in thread 588:
15: #20 Object "", at 0xffffffffffffffff, in
15: =================================================================
15: ==587==ERROR: AddressSanitizer: allocator is out of memory trying to allocate 0x36a8 bytes
15: ==587==ERROR: AddressSanitizer failed to allocate 0x1000 (4096) bytes of InternalMmapVector (error code: 12)
15: ERROR: Failed to mmap
1/1 Test #15: BufferPoolManagerTest.HardTest_1 ...***Failed 4.56 sec 1
2
3
4
5
6
7
8
915: Running main() from gmock_main.cc
15: Note: Google Test filter = BufferPoolManagerTest.HardTest_1
15: [==========] Running 1 test from 1 test suite.
15: [----------] Global test environment set-up.
15: [----------] 1 test from BufferPoolManagerTest
15: [ RUN ] BufferPoolManagerTest.HardTest_1
15: ==587==ERROR: AddressSanitizer failed to allocate 0x13f000 (1306624) bytes at address ff541264000 (errno: 12)
15: ==587==ReserveShadowMemoryRange failed while trying to map 0x13f000 bytes. Perhaps you're using ulimit -v
1/1 Test #15: BufferPoolManagerTest.HardTest_1 ...Subprocess aborted***Exception: 4.64 sec
errno说明内存不足,gradescope中分的虚拟内存不足以支持该测试,说明我的程序在内存管理上面需要改进或者有漏洞
- 1.
log:输出:1
2
3
4
5
6
7
815: FetchPage invoke 2470
15: UnpinPage: invoke 2470 0
15: DeletePage: invoke 2470
15: FetchPage invoke 8925
15: UnpinPage: invoke 8925 0
15: Del==587==ERROR: AddressSanitizer failed to allocate 0x13f000 (1306624) bytes at address fefff684000 (errno: 12)
15: ==587==ReserveShadowMemoryRange failed while trying to map 0x13f000 bytes. Perhaps you're using ulimit -v
1/1 Test #15: BufferPoolManagerTest.HardTest_1 ...Subprocess aborted***Exception: 6.35 sec复现:- 创建
10容量,5k的BPM - 重复下列操作,创建
10000个page:- 连续调用
NewPage10 次,连续对上述pages调用UnpinPage10次,前5个is_dirty为0,后5个is_dirty为1
- 连续调用
- 对
10000个page重复下列操作:- 调用
FetchPage,调用UnpinPage,调用DeletePage
- 调用
- 创建
- [✅]
Ubuntu能支持LLVM的内存泄漏检测,但是MacOS不支持:- 尝试
Ubuntu测试上述复现的Test:发现并没有任何内存泄漏
- 尝试
- [❎]
pages_的索引我没有假设一定是frame_id,只是调用自己写的工具函数GetFreePageForPageId遍历page_并找到第一个PageId为Invalid的Page对象.- - [❎] 尝试假设:
page_的索引就是frame_id,并且删除工具函数- - [❎] 此时会有很多之前通过的测试未通过(包括
LRUReplace),不清楚为什么- - [❎]
LRUReplacerTest.Evict该测试中:- 新建一个容量为
1000,k为3的replacer,然后依次从0到1000RecordAccess并且SetEvictable:但是出现如下问题:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22125SetEvictable: invoke 241 1
21: curr_size:241
21: not evictable -> on
21: curr_size:242
21: 92RecordAccess invoke 242
21: curr_size:242
21: note exist
21: curr_size:242
21: 125SetEvictable: invoke 242 1
21: curr_size:242
21: not evictable -> on
21: curr_size:243
21: 92RecordAccess invoke 243
21: curr_[...(truncated)...] invoke 844 1
21: curr_size:1000
21: curr_size:1000
21: 92RecordAccess invoke 845
21: curr_size:1000
21: exist
21: curr_size:1000
21: 125SetEvictable: invoke 845 1
21: curr_size:1000- - [❎]尝试
reproduce test- 复现测试场景居然是没问题的,,,,很困惑
- - [❎]尝试
- 新建一个容量为
- - [❎]
- - [❎] 此时会有很多之前通过的测试未通过(包括
- - [❎] 尝试假设:
吸取的教训:
- 先确保前面的实现是正确的:并发安全/线程执行顺序正确等
- 后续再在基础上进行优化:
交了100多次,换来的100分,
把gradescope当成debugger- 这还是在打log并复现
Tests的情况下 - 今后需要避免多次提交
- 这还是在打log并复现
通过本地测试+通过gradescope(低性能)一共3+5天
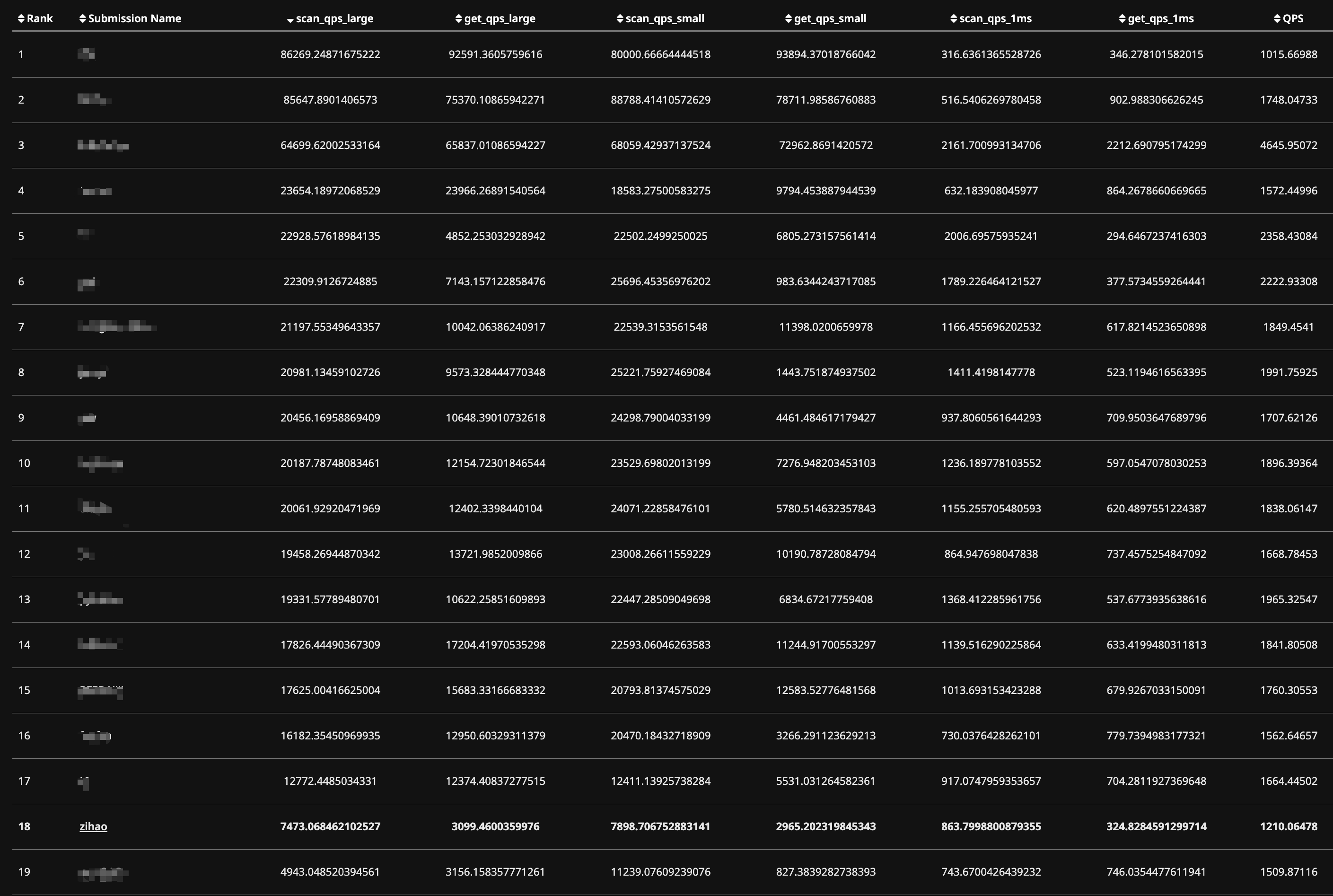
个人认为可以进行的优化
- - [ ] 当前
DiskScheduler中BackgroundWorker中创建的线程是串行,优化需要在确保顺序正确的情况下,使之适当并行执行 - - [ ] 并发问题,虽然在合适的地方加了锁,但是
latch_持有的范围可以缩小- - [ ] 当前
DiskScheduler中BackgroundWorker中创建的线程是串行,需要在确保顺序正确的情况下,使之适当并行执行
- - [ ] 当前
- - [ ] 改进递归锁/scope_lock开销
- - [ ] Mutiple buffer pools: 创建多个Buffer Pools,并使用Hashing进行控制用哪个buffer pool
- - [ ] LRU List:按照k backward distance的顺序将pages串联起来
- - [ ] Buffer Pool Pass:但是测试的请求信息中似乎没有标注是什么operator
具体见下一篇文章






